Classifying Data Center IP Addresses in Phoenix Web Applications with Radix Trees
Michael Lubas, 2022-05-10
Several cloud hosting companies publish the IP address ranges of their services. Examples include AWS, Azure, GCP, Oracle, and DigitalOcean. This information is useful to website owners, because the expected behavior of a client coming from a cloud server is different from a residential IP address. Consider a website that sells concert tickets, and wants to prevent bots from quickly purchasing all available tickets. The website owner notices that when tickets go on sale, hundreds of clients with data center IP addresses are making automated requests, purchasing tickets for resale before real visitors can.
This tutorial will demonstrate how to classify incoming requests to a Phoenix web application. This is based on a comparison of the request’s IP address with a data structure containing the IP ranges of several cloud providers. It will cover:
- How to retrieve lists of data center IP prefixes when a Phoenix application starts.
- Using a radix tree to store IP prefixes for fast lookup.
- Why Erlang's persistent_term module is the best choice for this problem.
- Using assigns to store metadata about the IP address.
- Writing a plug to block data center IP addresses.
The example of classifying IP addresses as belonging to cloud providers is meant as a concrete example to demonstrate several concepts related to Elixir programming and Phoenix web applications. The relevant code may be found on Github, see https://github.com/paraxialio/taxon
Definitions:
“Data Center IP Address” - An IP address that originates from a data center, not a residential area. For this tutorial, the term “data center” is used to refer to the servers provided by a cloud hosting service, such as AWS. A program running on an AWS hosted server is said to have a data center IP address.
“Residential IP Address” - An IP address that has been assigned to a residential home by an ISP. If you are reading this article from your home, and connected to WiFi, you are most likely using a residential IP address.
“Cloud Server” - A server that is available for rent from a hosting provider. These servers have a data center IP, not a residential IP.
1. Setup a New Phoenix application, Taxon
You will create a Phoenix application for this tutorial named Taxon. The code examples and commands below were run on a machine using Elixir 1.13 and Phoenix 1.6.
Create the Taxon application by running:
mix phx.new taxon
Run the following to setup Taxon:
cd taxon
mix deps.get
mix ecto.setupThen start the application locally with:
mix phx.serverOpen http://localhost:4000/ in your web browser. If you see the “Welcome to Phoenix!” page, continue to the next section.
2. A Plan for the Work
To classify incoming requests as “from a data center IP” or “not from a data center IP”, you will use the IP address ranges provided by cloud companies. At a high level, the plan is to:
- Determine which cloud providers to use for classifying traffic.
- Write a function for each cloud provider that makes an HTTP request to get a list of IP prefixes
- Once the IP prefixes have been downloaded, store them in a data structure with fast read access.
2.1. The Cloud Providers, Amazon and Microsoft
This tutorial uses two cloud providers as the source of IP prefixes, Amazon and Microsoft. The relevant prefixes can be found at the URLs:
AWS - https://ip-ranges.amazonaws.com/ip-ranges.json
Microsoft - https://download.microsoft.com/download/7/1/D/71D86715-5596-4529-9B13-DA13A5DE5B63/ServiceTags_Public_20220425.json
Observe the data from Amazon:
...
"prefixes": [
{
"ip_prefix": "3.5.140.0/22",
...
{
"ipv6_prefix": "2600:1f70:4000::/56",
...At the time of writing, the Amazon JSON file contains a few thousand IP prefixes. The next task to convert them into a data structure for fast matching against incoming requests.
3. IP Prefixes and Fast Comparison
The IPv4 prefix 3.5.140.0/22 has a host range of 3.5.140.0 - 3.5.143.255, with a total of 1022 usable IP addresses. The IPv6 prefix 2600:1f70:4000::/56 represents a massive number of IP addresses, over 4 sextillion. With this in mind, lets examine why a naive approach to this problem is likely to fail.
3.1. Converting the CIDR notation prefix to the full range of IP addresses, stored in an Elixir list or MapSet.
The problem with storing such a large amount of information in a list is two-fold. First, in Elixir lists have a search time complexity of O(n). Second, the IPv6 prefixes will consume an excessive amount of memory when stored in a list.
Using a MapSet data structure improves the search time complexity (from O(n) with a list to O(log n)), however the memory usage problem remains.
3.2. Store the prefix strings in a list, check if incoming IPs match each one.
This is a slightly better solution than the previous example, but still not ideal. Consider the two IP prefixes 3.5.140.0/22 and 2600:1f70:4000::/56. It requires the conversion of the prefixes into some kind of data structure, where it’s possible to quickly determine if 3.5.140.7 matches 3.5.140.0/22.
If you convert each prefix string into a bit representation, then compare the incoming IP address against each prefix’s bit representation, each of those operations will be fast. However, you cannot use a set data structure, because the prefixes are not acting as keys. This requires a list, where the search operation means iterating through every item in the list, which is still O(n).
In this example, the idea of converting the IP prefix into a bit representation was introduced. This hints at the idea that storing a large number of IP prefixes in memory is possible to do efficiently, and likely involves the bit representation of the prefix.
3.3. Convert each prefix into a bit representation, store in an ETS table with ordered_set.
A potential solution worth mentioning that is not implemented in this tutorial. See Adam Cammack’s reply on the erlang-questions mailing list.
4. Radix trees in Elixir with Iptrie
A key part of this IP matching problem is that IP addresses can be represented in binary. Consider a simplified problem:
Store the bit representation of the following integers in a tree:
0 - 0000
1 - 0001
2 - 0010
3 - 0011
8 - 1000
- Start at bit number 0, which is 0 for each integer except 8.
- Create a node with the current bit number, and pointers to the next leaf nodes
- For a next value of 0, point left
- For a next value of 1, point right
- Each leaf node increments the bit number by 1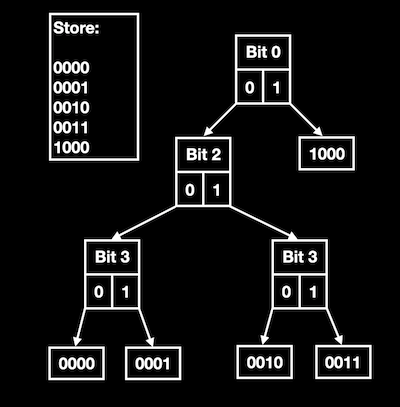
Using the above tree, to determine if the integer 8 is stored in the tree, you first ask, “What is the bit at position 0 in 1000 set to?”, and determine it is 1. Moving down and to the right, you arrive at the bit representation of 8 in the tree, and have your answer.
The tree that was just shown here is called a radix tree (or radix trie), an ideal data structure for the problem of storing IP addresses, and quickly checking if one IP address matches against a number of prefixes. There is an excellent package for the problem of IP address matching that implements radix trees in Elixir, Iptrie.
Consider three IP prefixes and their bit representation:
1. 128.0.0.0/8, 1000 0000 0000 0000 0000 0000 0000 0000
2. 1.2.3.0/24, 0000 0001 0000 0010 0000 0011 0000 0000
3. 0.0.0.0/0, 0000 0000 0000 0000 0000 0000 0000 0000Compare the above bit representations with this image from the Iptrie documentation:
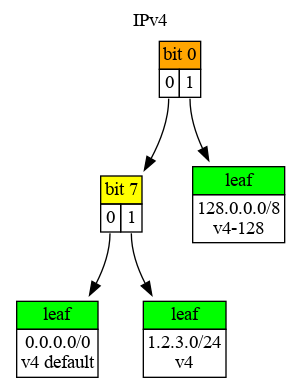
You want to determine if the tree contains 1.2.3.0/24. Start at the top, and consider the bit representation of 1.2.3.0/24. Does it start with a 0 or a 1? It starts with a 0, so go left. The new node states bit 7. Remember the bit counting index starts at 0, then find if bit 7 of 1.2.3.0/24. Is a 0 or a 1? You should see that the bit is 1, which means go right and down the tree. You’ve reached the leaf containing 1.2.3.0/24.
This information is represented in Iptrie as follows:
# You must store a key/value pair. Here "true" is used, a potential use is storing
# the cloud hosting provider each IP prefix originated from
iex(5)> Iptrie.new([{"128.0.0.0/8", true}, {"1.2.3.0/24", true}, {"0.0.0.0/0", true}])
%{
32 => {0, {7, [{"", true}], [{<<1, 2, 3>>, true}]}, [{<<128>>, true}]},
:__struct__ => Iptrie
}Several pieces of software you may be familiar with use radix trees. This includes:
- Nginx - https://github.com/nginx/nginx/blob/master/src/core/ngx_radix_tree.c
- Squid - https://wiki.squid-cache.org/ProgrammingGuide/SquidComponents
- Linux - https://lwn.net/Articles/175432
5. When Taxon Starts, Fetch the IP Prefixes
Now that you have a plan for the work, write a module, Fetcher, that performs the following tasks:
- Make an HTTP request to the appropriate cloud provider to obtain a list of IP prefixes.
- Parse the response from the server, extracting IP prefixes from the JSON.
- Construct an Iptrie from the list of IP prefixes.
- Store the Iptrie with persistent_term.
Open the mix.exs file for Taxon, install HTTPoison, Iptrie, and remove “only: :test” from Floki:
defp deps do
[
{:phoenix, "~> 1.6.6"},
{:floki, ">= 0.30.0"}, # Remove only: :test here
...
{:httpoison, "~> 1.8"},
{:iptrie, "~> 0.8.0"}
]
end
Create a new file, lib/taxon/fetcher.ex:
defmodule Taxon.Fetcher do
def add_cloud_ips() do
providers = %{
aws: "https://ip-ranges.amazonaws.com/ip-ranges.json",
azure: "https://www.microsoft.com/en-us/download/confirmation.aspx?id=56519"
}
get_prefixes_update_term(providers)
end
def get_prefixes_update_term(providers) do
# 1. Get the IP prefixes for each provider
# 2. Return a list of prefixes for each provider, if the HTTP request fails return []
new_prefixes =
Enum.map(providers, fn {cloud_provider, url} ->
Task.async(fn -> {cloud_provider, url_to_prefixes(url, cloud_provider)} end)
end)
|> Enum.map(&Task.await/1)
iptrie = prefixes_to_trie(new_prefixes)
:persistent_term.put({__MODULE__, :dc_trie}, iptrie)
IO.inspect(Iptrie.count(iptrie), label: "Iptrie count")
iptrie_size = iptrie |> :erlang.term_to_binary() |> :erlang.byte_size()
IO.inspect(iptrie_size / 1_000_000, label: "Iptrie_size in MB")
end
def prefixes_to_trie(pl) do
prefixes =
pl
|> Enum.map(fn {c, p} ->
IO.inspect(length(p), label: " prefixes for #{c}")
p
end)
|> List.flatten()
|> Enum.map(fn prefix -> {prefix, true} end)
IO.inspect(length(prefixes), label: "Total prefixes length (includes duplicates)")
Iptrie.new(prefixes)
end
def url_to_prefixes(url, :aws) do
with {:ok, %{status_code: 200, body: body}} <- HTTPoison.get(url),
{:ok, j_body} <- Jason.decode(body) do
ipv4 = extract_prefixes_aws(j_body, "prefixes", "ip_prefix")
ipv6 = extract_prefixes_aws(j_body, "ipv6_prefixes", "ipv6_prefix")
Enum.concat([ipv4, ipv6])
else
_ ->
[]
end
end
def url_to_prefixes(url, :azure) do
with {:ok, %{status_code: 200, body: body}} <- HTTPoison.get(url),
{:ok, json_url} <- get_json_url(body),
{:ok, %{status_code: 200, body: json_body}} <-
HTTPoison.get(json_url, [], follow_redirect: true),
{:ok, jd_body} <- Jason.decode(json_body) do
extract_prefixes_azure(jd_body)
else
_ ->
[]
end
end
def get_json_url(body) do
{:ok, html} = Floki.parse_document(body)
json_url =
html
|> Floki.find("a, href")
|> Enum.map(fn {_a, l, _} ->
Enum.filter(l, fn {_k, v} -> String.contains?(v, ".json") end)
end)
|> Enum.filter(fn x -> x != [] end)
|> hd()
|> hd()
|> elem(1)
{:ok, json_url}
end
def extract_prefixes_aws(body, k1, k2) do
body
|> Map.get(k1)
|> Enum.map(fn %{^k2 => prefix} -> prefix end)
end
def extract_prefixes_azure(body) do
body
|> Map.get("values")
|> Enum.map(fn x -> get_in(x, ["properties", "addressPrefixes"]) end)
|> List.flatten()
end
end
add_cloud_ips/0 is where a map is defined of cloud providers and the URL of their IP ranges. get_prefixes_update_term/1 uses Task.async to make the HTTP requests and parse the responses into lists of IP prefixes. These prefixes are used to create the iptrie, which is stored as a persistent term for fast access by many processes.
Edit lib/taxon/application.ex:
defmodule Taxon.Application do
use Application
@impl true
def start(_type, _args) do
# Add this line
Taxon.Fetcher.add_cloud_ips()
children = [
# Start the Ecto repository
Taxon.Repo,
When your application starts, add_cloud_ips/0 will run, populating the persistent_term value.
5. Plug Matching and Assigns
Create a new file, lib/taxon/data_center_plug.ex, and enter:
defmodule Taxon.DataCenterPlug do
import Plug.Conn
def init(opts), do: opts
def call(conn, _opts) do
iptrie = :persistent_term.get({Taxon.Fetcher, :dc_trie})
lookup = Iptrie.lookup(iptrie, conn.remote_ip)
if is_nil(lookup) do
IO.puts("Not data_center_ip")
assign(conn, :data_center_ip, false)
else
IO.puts("A data_center_ip")
assign(conn, :data_center_ip, true)
end
end
end
Every incoming request to the Taxon Phoenix application will pass through this plug. Add it to the router file, lib/taxon_web/router.ex:
defmodule TaxonWeb.Router do
use TaxonWeb, :router
pipeline :browser do
plug :accepts, ["html"]
plug :fetch_session
plug :fetch_live_flash
plug :put_root_layout, {TaxonWeb.LayoutView, :root}
plug :protect_from_forgery
plug :put_secure_browser_headers
plug Taxon.DataCenterPlug # Add this line
end
pipeline :api do
plug :accepts, ["json"]
plug Taxon.DataCenterPlug # Add this line
end
Start the application with mix phx.server, then visit http://localhost:4000/ in your web browser, and refresh the page a few times. You should an output similar to:
[info] GET /
[debug] Processing with TaxonWeb.PageController.index/2
Parameters: %{}
Pipelines: [:browser]
Not data_center_ip
[info] Sent 200 in 1ms
To confirm everything is working, spoof the remote_ip of the incoming conn by editing lib/taxon/data_center_plug.ex.
defmodule Taxon.DataCenterPlug do
import Plug.Conn
def init(opts), do: opts
def call(conn, _opts) do
aws_ip = {3, 5, 140, 2} # Add this line, AWS IP
conn = Map.put(conn, :remote_ip, aws_ip) # Add this line
iptrie = :persistent_term.get({Taxon.Fetcher, :dc_trie})
lookup = Iptrie.lookup(iptrie, conn.remote_ip)
if is_nil(lookup) do
IO.puts("Not data_center_ip")
assign(conn, :data_center_ip, false)
else
IO.puts("A data_center_ip")
assign(conn, :data_center_ip, true)
end
end
endNow refresh the page and you should see:
[info] GET /
[debug] Processing with TaxonWeb.PageController.index/2
Parameters: %{}
Pipelines: [:browser]
A data_center_ip
[info] Sent 200 in 1ms
The Taxon application is now classifying data center IP addresses from AWS and Azure. To demonstrate how this assigns can be used by other plugs, create a new file, lib/taxon/block_dc_ip.ex
defmodule Taxon.BlockDCIP do
import Plug.Conn
def init(opts), do: opts
def call(conn, _opts) do
if conn.assigns[:data_center_ip] do
conn
|> halt()
|> send_resp(404, "Not found")
else
conn
end
end
end
Open lib/taxon_web/router.ex
pipeline :api do
plug :accepts, ["json"]
plug Taxon.DataCenterPlug
end
# Add this pipeline
pipeline :block_dc do
plug Taxon.BlockDCIP
end
scope "/", TaxonWeb do
pipe_through :browser
get "/", PageController, :index
end
# Add this scope
scope "/", TaxonWeb do
pipe_through [:browser, :block_dc]
get "/no_dc", PageController, :no_dc
end
Now that the plug and router pipelines have been set, open lib/taxon_web/controllers/page_controller.ex:
defmodule TaxonWeb.PageController do
use TaxonWeb, :controller
def index(conn, _params) do
render(conn, "index.html")
end
# Add this action
def no_dc(conn, _params) do
render(conn, "no_dc.html")
end
end
Create a new file, lib/taxon_web/templates/page/no_dc.html.eex:
<h2>Data center IPs cannot view this page.</h2>
Open lib/taxon/data_center_plug.ex and comment out the remote_ip spoof:
defmodule Taxon.DataCenterPlug do
import Plug.Conn
def init(opts), do: opts
def call(conn, _opts) do
#aws_ip = {3, 5, 140, 2} # Add this line, AWS IP
#conn = Map.put(conn, :remote_ip, aws_ip) # Add this line
iptrie = :persistent_term.get({Taxon.Fetcher, :dc_trie})
lookup = Iptrie.lookup(iptrie, conn.remote_ip)
if is_nil(lookup) do
IO.puts("Not data_center_ip")
assign(conn, :data_center_ip, false)
else
IO.puts("A data_center_ip")
assign(conn, :data_center_ip, true)
end
end
end
Run the application with mix phx.server and open http://localhost:4000/no_dc in your web browser. You should see the Phoenix Framework logo and the text “Data center IPs cannot view this page.”.
Now uncomment the remote_ip spoof in lib/taxon/data_center_plug.ex:
...
def call(conn, _opts) do
aws_ip = {3, 5, 140, 2} # Add this line, AWS IP
conn = Map.put(conn, :remote_ip, aws_ip) # Add this line
iptrie = :persistent_term.get({Taxon.Fetcher, :dc_trie})
...Open http://localhost:4000/no_dc again, and you should see “Not found”.
6. ETS vs Persistent Term
Consider an alternate implementation of Taxon, where the Iptrie is stored in an ETS table:
:ets.insert(:dc_all, {:dc_all_trie, ip_trie})
Then on every incoming conn:
[dc_all_trie: ip_trie] = :ets.lookup(:dc_all, :dc_all_trie)This is a typical use case for ETS, and may be acceptable for tries with under 100,000 prefixes. On an M1 MacBook Air with 8GB of memory:
- 100,000 fake IPv4 prefixes used to create ip_trie
- 288 requests per second to the root path
The median response time increases to 6ms. This seems small, however another increase to 1 million fake prefixes renders the entire system unusable due to high memory usage. The implementation with persistent_term handles this load well.
This happens because every process accessing ip_trie through ETS gets a copy of data structure. In some cases it is possible to avoid this problem, for example when the data stored in ETS is a binary format, it is stored in a shared heap. The blog post Avoiding GenServer bottlenecks (2018) by Jake Morrison uses the example of GeoIP lookups to discuss this topic. It is worth noting that version 2.0.0 of Locus, a MaxMind DB reader, uses persistent_term instead of ETS.
For some time many programs used the constant pools optimization to achieve quick access to large shared data, see the FastGlobal library from Discord. With the introduction of persistent_term, this technique is considered obsolete.
There is an important consideration when using persistent_term, related to updates and deletes. From the documentation, “This module is similar to ets in that it provides a storage for Erlang terms that can be accessed in constant time, but with the difference that persistent_term has been highly optimized for reading terms at the expense of writing and updating terms. When a persistent term is updated or deleted, a global garbage collection pass is run to scan all processes for the deleted term, and to copy it into each process that still uses it. Therefore, persistent_term is suitable for storing Erlang terms that are frequently accessed but never or infrequently updated.”
Due to the global garbage collection, frequently updating a persistent_term is discouraged. For the problem of classifying IPs defined here, it works well. Design of a solution where Iptrie needs to be frequently updated is left for future work.
7. Future Work
This tutorial does not go into detail on some topics that may be of interest, such as:
- Identifying which cloud provider an IP address matched.
- Tagging IP addresses with additional details (GeoLocation, Tor Exit Node, VPN).
- Using ExUnit to test the implementation more thoroughly.
- Storing a historical record of cloud provider IP prefixes in a database.
- Design of a system where Iptrie is frequently updated.
It is important to note that in a deployed Phoenix application, conn.remote_ip will likely not be the real client IP. The remote_ip project solves this.
Thank you to hertogp for creating Iptrie and related projects.
Paraxial.io stops data breaches by helping developers ship secure applications. Get a demo or start for free.